## 使用手工编译的clang执行如下指令 ## -fmodules Enable the 'modules' language feature ## This will make any modules-enabled software libraries available as modules as well as introducing any modules-specific syntax. ## -E Only run the preprocessor ## 只运行预处理器 ## -Xclang <arg> Pass <arg> to the clang compiler ## -dump-tokens -- man clang/ clang --help 都没不到 ## 参考1 ## http://clang.llvm.org/doxygen/namespaceclang_1_1driver_1_1options.html ## enum clang::driver::options::ClangFlags ## Flags specifically for clang options.
## 参考2 ## Running the plugin ## Using the cc1 command line ## To run a plugin, the dynamic library containing the plugin registry # must be loaded via the -load command line option. This will load all plugins that are registered, and you can select the plugins to run by specifying the -plugin option. Additional parameters for the plugins can be passed with -plugin-arg-<plugin-name>. ## Note that those options must reach clang’s cc1 process. There are two ways to do so:
// The lexer returns tokens [0-255] if it is an unknown character, otherwise one // of these for known things. // 字符流解析词元规则,要么是如下5种类型,要么返回对应的ASCII值 enum Token { tok_eof = -1,
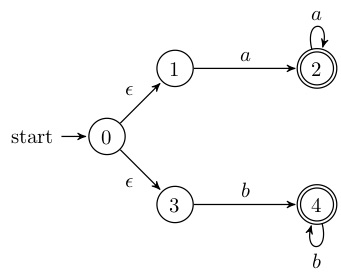
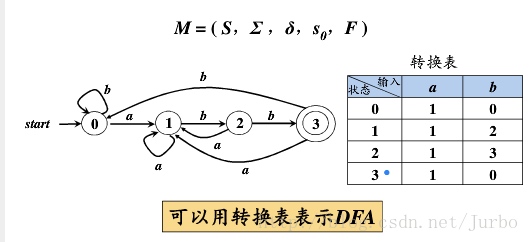
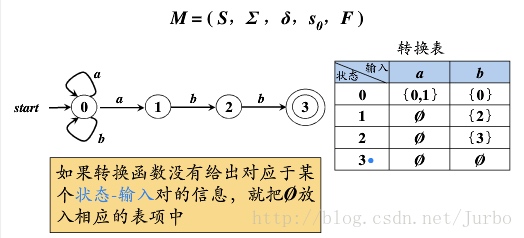
split(s) foreach(character c) /** 输入字符c到状态集合s中,每种状态输出的状态集存在不一致的情况,证明字符c可以切割这个状态集合s */ if (c can split s) split s into T1,...,Tk hopcroft() /** 首次划分: N非结束状态,A结束状态 */ split all nodes into N,A while(set is still changes) split(s)
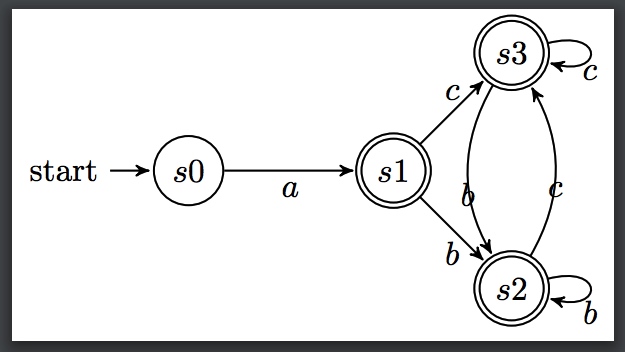
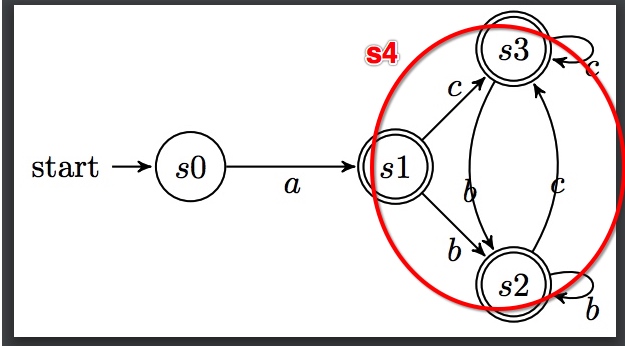
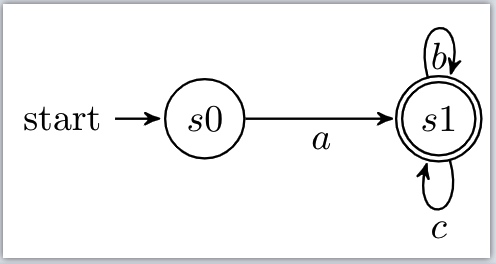
将所有终止状态合并为状态s4
该状态s4接收字符b,c
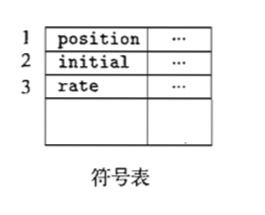
1 2 3 4 5 6 7 8 9
用字符b尝试切割
状态1 输入 b 得到状态2 在状态s4中 状态2 输入 b 得到状态2 在状态s4中 状态3 输入 b 空集 忽略
voidPreprocessor::Lex(Token &Result){ // We loop here until a lex function returns a token; this avoids recursion. bool ReturnedToken; do { switch (CurLexerKind) { case CLK_Lexer: ReturnedToken = CurLexer->Lex(Result); break; case CLK_TokenLexer: ReturnedToken = CurTokenLexer->Lex(Result); break; case CLK_CachingLexer: CachingLex(Result); ReturnedToken = true; break; case CLK_LexAfterModuleImport: LexAfterModuleImport(Result); ReturnedToken = true; break; } } while (!ReturnedToken);
if (Result.is(tok::code_completion) && Result.getIdentifierInfo()) { // Remember the identifier before code completion token. setCodeCompletionIdentifierInfo(Result.getIdentifierInfo()); setCodeCompletionTokenRange(Result.getLocation(), Result.getEndLoc()); // Set IdenfitierInfo to null to avoid confusing code that handles both // identifiers and completion tokens. Result.setIdentifierInfo(nullptr); }
/// Token - This structure provides full information about a lexed token. /// It is not intended to be space efficient, it is intended to return as much /// information as possible about each returned token. This is expected to be /// compressed into a smaller form if memory footprint is important. /// /// The parser can create a special "annotation token" representing a stream of /// tokens that were parsed and semantically resolved, e.g.: "foo::MyClass<int>" /// can be represented by a single typename annotation token that carries /// information about the SourceRange of the tokens and the type object. classToken { /// The location of the token. This is actually a SourceLocation. unsigned Loc;
// Conceptually these next two fields could be in a union. However, this // causes gcc 4.2 to pessimize LexTokenInternal, a very performance critical // routine. Keeping as separate members with casts until a more beautiful fix // presents itself.
/// UintData - This holds either the length of the token text, when /// a normal token, or the end of the SourceRange when an annotation /// token. /// token 的长度 unsigned UintData;
/// PtrData - This is a union of four different pointer types, which depends /// on what type of token this is: /// Identifiers, keywords, etc: /// This is an IdentifierInfo*, which contains the uniqued identifier /// spelling. /// Literals: isLiteral() returns true. /// This is a pointer to the start of the token in a text buffer, which /// may be dirty (have trigraphs / escaped newlines). /// Annotations (resolved type names, C++ scopes, etc): isAnnotation(). /// This is a pointer to sema-specific data for the annotation token. /// Eof: // This is a pointer to a Decl. /// Other: /// This is null. /// token的内容 void *PtrData;
/// Kind - The actual flavor of token this is. /// token的类型 tok::TokenKind Kind;
/// Flags - Bits we track about this token, members of the TokenFlags enum. unsignedshort Flags;
/// Provides a simple uniform namespace for tokens from all C languages. enumTokenKind :unsignedshort { #define TOK(X) X, #include"clang/Basic/TokenKinds.def" NUM_TOKENS };
/// Provides a namespace for preprocessor keywords which start with a /// '#' at the beginning of the line. enumPPKeywordKind { #define PPKEYWORD(X) pp_##X, #include"clang/Basic/TokenKinds.def" NUM_PP_KEYWORDS };
/// Provides a namespace for Objective-C keywords which start with /// an '@'. enumObjCKeywordKind { #define OBJC_AT_KEYWORD(X) objc_##X, #include"clang/Basic/TokenKinds.def" NUM_OBJC_KEYWORDS };
// clang/Basic/TokenKinds.def ... // C99 6.4.2: Identifiers. TOK(identifier) // abcde123 TOK(raw_identifier) // Used only in raw lexing mode.
/// Lexer.cpp /// LexTokenInternal - This implements a simple C family lexer. It is an /// extremely performance critical piece of code. This assumes that the buffer /// has a null character at the end of the file. This returns a preprocessing /// token, not a normal token, as such, it is an internal interface. It assumes /// that the Flags of result have been cleared before calling this. /// 词法分析的方法 boolLexer::LexTokenInternal(Token &Result, bool TokAtPhysicalStartOfLine) ... // Read a character, advancing over it. char Char = getAndAdvanceChar(CurPtr, Result); tok::TokenKind Kind; /// 遍历字符 switch (Char) { ... case'\n': // If we are inside a preprocessor directive and we see the end of line, // we know we are done with the directive, so return an EOD token. if (ParsingPreprocessorDirective) { // Done parsing the "line". ParsingPreprocessorDirective = false;
// Restore comment saving mode, in case it was disabled for directive. if (PP) resetExtendedTokenMode();
// Since we consumed a newline, we are back at the start of a line. IsAtStartOfLine = true; IsAtPhysicalStartOfLine = true;
/// LexNumericConstant - Lex the remainder of a integer or floating point /// constant. From[-1] is the first character lexed. Return the end of the /// constant. boolLexer::LexNumericConstant(Token &Result, constchar *CurPtr){ ... /// 类型设置为 tok::numeric_constant FormTokenWithChars(Result, CurPtr, tok::numeric_constant); ...
/// 判断是否是标识符 boolLexer::LexIdentifier(Token &Result, constchar *CurPtr){ // Match [_A-Za-z0-9]*, we have already matched [_A-Za-z$] unsigned Size; unsignedchar C = *CurPtr++; ...